Introduction
Have you ever in the past used an online language translator to translate a sentence from one language to another? If so, you may have noticed that sometimes the translation doesn't quite make sense. The grammar might be incorrect, or the meaning might be lost in translation. This is because traditional machine translation systems are based on rules and patterns, and they struggle with the complexity and nuance of natural language. But how do newer Machine Translation tools, such as DeepL, achieve such precise translation in terms of both meaning and grammar?
Enter the transformer - a type of artificial neural network that has revolutionised machine translation and many other natural language processing tasks. Unlike traditional machine translation systems, transformers are based on a different approach to language processing, one that is inspired by how humans learn and use language.
Attention and Self-Attention
At a high level, transformers work by breaking down a sentence into its constituent parts, and then analysing the relationships between those parts to give meaning. They do this using a process called attention, which involves assigning weights to each word in a sentence based on how relevant it is to the overall meaning of the sentence. The attention weights allow the transformer to focus on the most important parts of a sentence, and to ignore the parts that are less important.
But how does the transformer learn to do this? It does so through a process called training, in which it is fed large amounts of text data in both the source language and the target language (for example, English and French). During training, the transformer learns to associate the words in the source language with their corresponding words in the target language, using a technique called self-attention. This allows the transformer to consider the relationships between all the words in a sentence, rather than just looking at individual pairs of words.
Encoding and Decoding
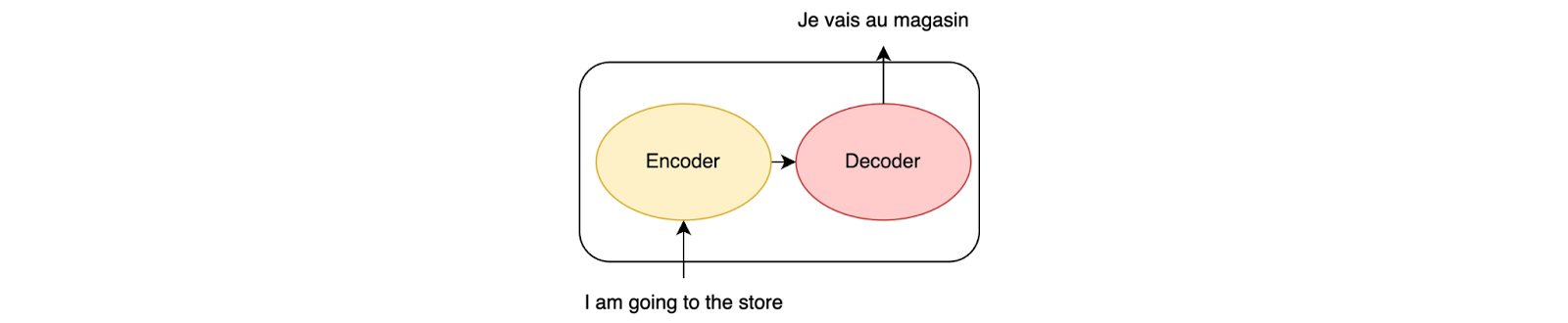
Once the transformer has been trained, it can be used to translate sentences from the source language to the target language. The transformer is made of two parts, encoder and decoder. Focusing on the encoder, the transformer converts the source sentence into a sequence of vectors, one for each word, through a process called encoding. The encoder uses self-attention to generate a weighted representation of each word in the sentence, which is then combined to produce a single vector representation of the entire sentence.
The encoder and decoder each consist of multiple layers (e.g., 12 or more layers for large models like GPT-3), enabling them to learn complex patterns and relationships through their deep architecture.
The transformer uses the encoded sentence to create a new series of steps that represent the translated sentence in the language we want. This is done through a process called decoding. The transformer (the decoder part) creates one word at a time, considering the words already created and the original sentence's encoded form. The decoder pays attention to the relationships between all the words in the sentence while generating each word.
During the decoding process, the decoder not only uses self-attention to consider the target language context but also incorporates information from the encoder using cross-attention. This allows the decoder to take into account both the target language context and the source language context when generating the translated sentence.
Applications
Transformers are not only useful for machine translation, but also for a wide range of other natural language processing tasks, such as text summarisation, sentiment analysis, and question answering. Their ability to learn from large amounts of text data and to comprehend the complex relationships between words has made them a powerful tool for understanding and processing human language.
What else?
In conclusion, transformers represent a major breakthrough in the field of natural language processing. By using attention and self-attention to analyse the relationships between words in a sentence, and by using encoder-decoder architectures to translate between languages, transformers have enabled significant improvements in machine translation and many other natural language processing tasks. As the field continues to evolve, we can expect to see even more applications of this powerful technology in the years to come.
Artificial General Intelligence (AGI) refers to a form of AI that can understand or learn any intellectual task that a human being can do. However, while transformers like ChatGPT are certainly impressive, it's important to remember that they are not a true form of artificial general intelligence (AGI). While LLMs have made significant progress in natural language processing, they are still far from being able to fully understand and replicate the complexity and nuance of human language. They are still limited in their ability to think creatively, reason abstractly, and generalise knowledge across different domains. As the field of AI continues to evolve, it's important to keep in mind the limitations of current technology and to explore new approaches to achieving true AGI.